Introduction to the hdf5r package
Holger Hoefling
April 17th 2016
Source:vignettes/hdf5r.Rmd
hdf5r.RmdAbstract
Overview on how to use the simple as well as advanced facilities of HDF5 using the hdf5r package
Introduction
HDF5 is a data model, library, and file format for storing and managing data. It supports an unlimited variety of datatypes, and is designed for flexible and efficient I/O and for high volume and complex data.
As R is very often used to process large amounts of data, having a direct interface to HDF5 is very useful. As of the writing of this vignette, there are 2 other packages available that also implement an interface to HDF5, h5 on CRAN and rhdf5 on Bioconductor. These are also good implementations, but there are several points that make this package here – hdf5r – stand out:
- User friendly interface that allows access to datasets in the same fashion a user would access regular R arrays
- All HDF5 classes are implemented using R6 classes, allowing for a very simple way of manipulating objects
- The library is almost feature complete, implementing most of the functionality of the HDF5 C-API. Some exceptions are for example functions that expect other C-functions as arguments.
- It ships with the newest version 1.10.0 of HDF5
- All HDF5 constants and datatypes are available under their regular name.
- All HDF5 functions that return constants do this in the format of an extended-factor-variable, giving the constants value as well as the name. Furthermore, all functions that in HDF5 return C-structs, return a data frame with the same variable names as in the structs (usually used by the various “-info” functions).
- Tracking and closing of unused HDF5 resources is done completely automatically using the R garbage collector.
In the following sections of this vignette, first a simple example will be given that shows how standard operations are being performed. Next, more advanced features will be discussed such as the creation of complex datatypes, datasets with special datatypes, the setting of the various available filters when reading/writing a package etc. We will end with a technical overview on the underlying implementation.
A simple example
As an introduction on how to use it, let us set up a very simple usage example. We will create a file, some groups in it as well as datasets of different sizes. We will read and write data, delete datasets again, get information on various objects.
Creating files, groups and datasets
But first things first. We create a random filename in a temporary directory and create a file with read/write access, deleting it if it already exists (it won’t - tempfile gives us a name of a file that doesn’t exist yet).
library(hdf5r)
test_filename <- tempfile(fileext = ".h5")
file.h5 <- H5File$new(test_filename, mode = "w")
file.h5## Class: H5File
## Filename: /tmp/Rtmp9dznhn/file3c2943fb1c5a1.h5
## Access type: H5F_ACC_RDWRNow that we have this, we will create 2 groups, one for the mtcars dataset and one for the nycflights13 dataset.
mtcars.grp <- file.h5$create_group("mtcars")
flights.grp <- file.h5$create_group("flights")Into these groups, we will now write the datasets
library(datasets)
library(nycflights13)
library(reshape2)
mtcars.grp[["mtcars"]] <- datasets::mtcars
flights.grp[["weather"]] <- nycflights13::weather
flights.grp[["flights"]] <- nycflights13::flightsOut of the weather data, we extract the information on the wind-direction and wind-speed and will save it as a matrix with the hours in the columns and the days in the rows (only for weather station EWR, the others are not complete).
weather_wind_dir <- subset(nycflights13::weather, origin == "EWR", select = c("year",
"month", "day", "hour", "wind_dir"))
weather_wind_dir <- na.exclude(weather_wind_dir)
weather_wind_dir$wind_dir <- as.integer(weather_wind_dir$wind_dir)
weather_wind_dir <- acast(weather_wind_dir, year + month + day ~ hour, value.var = "wind_dir")## Aggregation function missing: defaulting to length
flights.grp[["wind_dir"]] <- weather_wind_dirand
weather_wind_speed <- subset(nycflights13::weather, origin == "EWR", select = c("year",
"month", "day", "hour", "wind_speed"))
weather_wind_speed <- na.exclude(weather_wind_speed)
weather_wind_speed <- acast(weather_wind_speed, year + month + day ~ hour, value.var = "wind_speed")## Aggregation function missing: defaulting to length
flights.grp[["wind_speed"]] <- weather_wind_speedFor completeness, we also attach the row and column names as attributes:
h5attr(flights.grp[["wind_dir"]], "colnames") <- colnames(weather_wind_dir)
h5attr(flights.grp[["wind_dir"]], "rownames") <- rownames(weather_wind_dir)
h5attr(flights.grp[["wind_speed"]], "colnames") <- colnames(weather_wind_speed)
h5attr(flights.grp[["wind_speed"]], "rownames") <- rownames(weather_wind_speed)Getting information about different objects
Content of files and groups
With respect to groups and files, we also want to have a simple way to extract the contents. With the names function, we can get all names of objects in a group or in the root directory of a file
names(file.h5)## [1] "flights" "mtcars"
names(flights.grp)## [1] "flights" "weather" "wind_dir" "wind_speed"Another option that gives more information is ls, a method of the classes H5File and H5Group
flights.grp$ls()## name link.type obj_type num_attrs group.nlinks group.mounted
## 1 flights H5L_TYPE_HARD H5I_DATASET 0 NA NA
## 2 weather H5L_TYPE_HARD H5I_DATASET 0 NA NA
## 3 wind_dir H5L_TYPE_HARD H5I_DATASET 2 NA NA
## 4 wind_speed H5L_TYPE_HARD H5I_DATASET 2 NA NA
## dataset.rank dataset.dims dataset.maxdims dataset.type_class
## 1 1 336776 Inf H5T_COMPOUND
## 2 1 26115 Inf H5T_COMPOUND
## 3 2 364 x 24 Inf x Inf H5T_INTEGER
## 4 2 364 x 24 Inf x Inf H5T_INTEGER
## dataset.space_class committed_type
## 1 H5S_SIMPLE <NA>
## 2 H5S_SIMPLE <NA>
## 3 H5S_SIMPLE <NA>
## 4 H5S_SIMPLE <NA>Information on attributes, datatypes and datasets
If you have an HDF5-File, it is of course important to look up various information not only about groups, but also about the information contained in it. First, we want to get more information about the dataset. ls on the group already gives a lot of information about the datatype, the size, the maximum size etc. However there are also other, more direct, ways to get the same information. In order to investigate the datatype we can
weather_ds <- flights.grp[["weather"]]
weather_ds_type <- weather_ds$get_type()
weather_ds_type$get_class()## [1] H5T_COMPOUND
## 13 Levels: H5T_NO_CLASS H5T_INTEGER H5T_FLOAT H5T_TIME ... H5T_NCLASSES
## 13 Values: -1 0 1 2 ... 11
cat(weather_ds_type$to_text())## H5T_COMPOUND {
## H5T_STRING {
## STRSIZE H5T_VARIABLE;
## STRPAD H5T_STR_NULLTERM;
## CSET H5T_CSET_ASCII;
## CTYPE H5T_C_S1;
## } "origin" : 0;
## H5T_STD_I32LE "year" : 8;
## H5T_STD_I32LE "month" : 12;
## H5T_STD_I32LE "day" : 16;
## H5T_STD_I32LE "hour" : 20;
## H5T_IEEE_F64LE "temp" : 24;
## H5T_IEEE_F64LE "dewp" : 32;
## H5T_IEEE_F64LE "humid" : 40;
## H5T_IEEE_F64LE "wind_dir" : 48;
## H5T_IEEE_F64LE "wind_speed" : 56;
## H5T_IEEE_F64LE "wind_gust" : 64;
## H5T_IEEE_F64LE "precip" : 72;
## H5T_IEEE_F64LE "pressure" : 80;
## H5T_IEEE_F64LE "visib" : 88;
## H5T_IEEE_F64LE "time_hour" : 96;
## }telling us that our dataset consists of a H5T_COMPOUND datatype and prints more detailed information on its content of every column. Regarding the size of the dataset and the size of the chunks (datasets are by default chunked; more about this below) we do:
weather_ds$dims
weather_ds$maxdims
weather_ds$chunk_dims## [1] 26115
## [1] Inf
## [1] 78In order to get information on attributes we also have various function available. Which attributes are attached to an object we can see with
h5attr_names(flights.grp[["wind_dir"]])## [1] "colnames" "rownames"and the content of one attribute can be extracted with h5attr, the content of all of them with a list as h5attributes.
h5attr(flights.grp[["wind_dir"]], "colnames")## [1] "0" "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14"
## [16] "15" "16" "17" "18" "19" "20" "21" "22" "23"Detailed information about various objects
In HDF5, there are also various ways of getting more detailed information about objects. The most detailed methods for this are
- get_obj_info: Various information on the number of attributes, the type of the object, the reference count, access times (if set to be recorded) and other more technical information
- get_link_info: For links, mainly yields information on the link type, i.e. hard link or soft link. The difference between them and how to create them will be discussed further below.
- get_group_info: Information about the storage type of the group, if a file is mounted to the group and the number of items in the group. For the casual user, the most interesting information is the number of items in the group, which can also be retrieved using the names function. For very large groups, this way is however more efficient.
- get_file_name: For an H5File or H5Group, H5D or H5T (where D is for dataset and T stands for a committed type) object, returns the name of the file it is in.
- get_obj_name: Similar as get_file_name, applies to the same object, but returns the path inside the file to the object
- file_info: It extracts relatively technical information about a file. It can only be applied to an object of class H5File. This function is usually not of interest to the casual user
Most of these are somewhat advanced. They key information can usually also be extracted with one of the “higher-level” methods shown above, but sometimes the info methods are more efficient.
Assigning data into datasets and deleting datasets
Of course we also want to to be able to read out data, change it, extend the dataset and also delete it again. Reading out the data works just as it does for regular R arrays and data frames. However, HDF5-tables only have one dimension, not two. It is currently not possible to selectively read columns - all of them have to be read at the same time. For arrays, any data point can be read on its without restrictions
weather_ds[1:5]## origin year month day hour temp dewp humid wind_dir wind_speed wind_gust
## 1 EWR 2013 1 1 1 39.02 26.06 59.37 270 10.35702 NA
## 2 EWR 2013 1 1 2 39.02 26.96 61.63 250 8.05546 NA
## 3 EWR 2013 1 1 3 39.02 28.04 64.43 240 11.50780 NA
## 4 EWR 2013 1 1 4 39.92 28.04 62.21 250 12.65858 NA
## 5 EWR 2013 1 1 5 39.02 28.04 64.43 260 12.65858 NA
## precip pressure visib time_hour
## 1 0 1012.0 10 1357020000
## 2 0 1012.3 10 1357023600
## 3 0 1012.5 10 1357027200
## 4 0 1012.2 10 1357030800
## 5 0 1011.9 10 1357034400
wind_dir_ds <- flights.grp[["wind_dir"]]
wind_dir_ds[1:3, ]## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## [1,] 0 1 1 1 1 1 1 1 1 1 1 1 0 1
## [2,] 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [3,] 1 1 1 1 1 1 1 1 1 1 1 0 1 1
## [,15] [,16] [,17] [,18] [,19] [,20] [,21] [,22] [,23] [,24]
## [1,] 1 1 1 1 1 1 1 1 1 1
## [2,] 1 1 1 1 1 1 1 1 1 1
## [3,] 1 1 1 1 1 1 1 1 1 1Let us replace one row. Currently, vector-recycling is not enabled, so you have to ensure that your replacements have the correct size. Recycling may be enabled in the future.
wind_dir_ds[1, ] <- rep(1, 24)
wind_dir_ds[1, ]## [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1It is also possible to add data outside the dimensions of the dataset as long as they are within the maxdims. The dataset will be expanded to accommodate the new data. When the expansion of the dataset leads to unassigned points, they are filled with the default fill value. The default fill value can be obtained using
wind_dir_ds$get_fill_value()## [1] 0
wind_dir_ds[1, 25] <- 1
wind_dir_ds[1:2, ]## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## [1,] 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [2,] 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## [,15] [,16] [,17] [,18] [,19] [,20] [,21] [,22] [,23] [,24] [,25]
## [1,] 1 1 1 1 1 1 1 1 1 1 1
## [2,] 1 1 1 1 1 1 1 1 1 1 0Now that we have expanded the dataset to have a 25th column, filled with 0s except for the first column, it only remains to show how to delete a dataset. However note: Deleting a dataset does not lead to a reduction in HDF5 file size, but the internal space can be re-used for other datasets later.
flights.grp$link_delete("wind_dir")
flights.grp$ls()## name link.type obj_type num_attrs group.nlinks group.mounted
## 1 flights H5L_TYPE_HARD H5I_DATASET 0 NA NA
## 2 weather H5L_TYPE_HARD H5I_DATASET 0 NA NA
## 3 wind_speed H5L_TYPE_HARD H5I_DATASET 2 NA NA
## dataset.rank dataset.dims dataset.maxdims dataset.type_class
## 1 1 336776 Inf H5T_COMPOUND
## 2 1 26115 Inf H5T_COMPOUND
## 3 2 364 x 24 Inf x Inf H5T_INTEGER
## dataset.space_class committed_type
## 1 H5S_SIMPLE <NA>
## 2 H5S_SIMPLE <NA>
## 3 H5S_SIMPLE <NA>Closing the file
As a last step, we want to close the file. For this, we have 2 options, the close and close_all methods of an h5-file. There are some non-obvious differences for novice users between the two. close will close the file, but groups and datatsets that are already open, will stay open. Furthermore, as along as any object is still open, the file cannot be re-opened in the regular fashion as HDF5 prevents a file from being opened more than once.
However, it can be quite cumbersome to close all objects associated with a file - that is if we even have still access to them. We may have created an object, discarded it, but the garbage collector hasn’t closed it yet.
In order to make this process simpler for the end-user, close_all closes the file as well as all objects associated with the file. Any R6-classes pointing to the object will automatically be invalidated. This way, if it is needed, the file can be re-opened again.
file.h5$close_all()As a rule - it is recommended to work in the following fashion. Open a file with H5File$new and store the resulting R6-class object. Do not discard this object. The current default behavior is to close the file, but not the objects inside the file if the garbage collector is triggered. This is done in order not to interfere with other open objects later, but as explained can prevent the the re-opening of the file later. Therefore, do not discard the R6-class pointing to a file - and close it later again using the **close_all* method in order to ensure that all IDs using the file are being closed as well.
Advanced features
HDF5 provides a very wide range of tools. Describing it here would certainly be a task that is too large for this vignette. For a complete overview on what HDF5 can do, the reader should have a look at the HDF5 website and the documentation that is listed there as well as specifically the reference manual. Most API-functions that are referenced there are already implemented (and any other missing functionality that is feasible will hopefully follow soon).
In this section we will will therefore only shine a spotlight on a number of low-level API functions that can be used in connection with creating datasets as well as datatypes.
Creating datasets
As we have already seen above, a dataset can be created by simply assigning an appropriate R object under a given name into a group or a file. The automatic algorithm then uses the size of the assigned object to determine the size of the HDF5 dataset, it makes assumptions about “chunking” that have an influence on the storage efficiency as well as the maximum possible size of the dataset.
However, we have much more control if we specify these things “by hand”. In the following example, we will create a dataset consisting of 2 bit unsigned integers (i.e. capable of storing values from 0 to 3). We will set the size of the dataset as well as the space and the chunk-size ourselves. As a first step, lets create the custom datatype
uint2_dt <- h5types$H5T_NATIVE_UINT32$set_size(1)$set_precision(2)$set_sign(h5const$H5T_SGN_NONE)Here we use a built-in constant and datatype. All constants can be
accessed using
h5const
Next we define the space that we will use for the dataset, where we want 10 columns and 10 rows. The number of columns will always be fixed, but the number of rows should be able to increase to infinity.
Next, we have to define with which properties the dataset should be created. We will set a default fill value of 1, enable n-bit filtering but no compression and set the chunk size to (10, 10).
ds_create_pl_nbit <- H5P_DATASET_CREATE$new()
ds_create_pl_nbit$set_chunk(c(10, 10))$set_fill_value(uint2_dt, 1)$set_nbit()Now lets put all this together and create a dataset.
uint2.grp <- file.h5$create_group("uint2")
uint2_ds_nbit <- uint2.grp$create_dataset(name = "nbit_filter", space = space_ds,
dtype = uint2_dt, dataset_create_pl = ds_create_pl_nbit, chunk_dim = NULL, gzip_level = NULL)
uint2_ds_nbit[, ] <- sample(0:3, size = 100, replace = TRUE)
uint2_ds_nbit$get_storage_size()## [1] 26And not lets compare what happens if we don’t have any filter, only compression and nbit as well as compression
ds_create_pl_nbit_deflate <- ds_create_pl_nbit$copy()$set_deflate(9)
ds_create_pl_deflate <- ds_create_pl_nbit$copy()$remove_filter()$set_deflate(9)
ds_create_pl_none <- ds_create_pl_nbit$copy()$remove_filter()
uint2_ds_nbit_deflate <- uint2.grp$create_dataset(name = "nbit_deflate_filter", space = space_ds,
dtype = uint2_dt, dataset_create_pl = ds_create_pl_nbit_deflate, chunk_dim = NULL,
gzip_level = NULL)
uint2_ds_nbit_deflate[, ] <- uint2_ds_nbit[, ]
uint2_ds_deflate <- uint2.grp$create_dataset(name = "deflate_filter", space = space_ds,
dtype = uint2_dt, dataset_create_pl = ds_create_pl_deflate, chunk_dim = NULL,
gzip_level = NULL)
uint2_ds_deflate[, ] <- uint2_ds_nbit[, ]
uint2_ds_none <- uint2.grp$create_dataset(name = "none_filter", space = space_ds,
dtype = uint2_dt, dataset_create_pl = ds_create_pl_none, chunk_dim = NULL, gzip_level = NULL)
uint2_ds_none[, ] <- uint2_ds_nbit[, ]With the sizes of the datasets
uint2_ds_nbit_deflate$get_storage_size()
uint2_ds_nbit$get_storage_size()
uint2_ds_deflate$get_storage_size()
uint2_ds_none$get_storage_size()## [1] 35
## [1] 26
## [1] 55
## [1] 100and we see that in the case of random data, not surprisingly, the nbit filter alone is the most efficient. Using compression on the nbit-filter actually increases the storage size. However, despite the random data, compression can still save some space compared to raw storage as in raw storage mode, a whole byte is stored and not just 2 bit.
Interacting with datatypes
Integer, Float
For integer-datatypes we have already seen that we have control over essentially everything, i.e. signed/unsigned as well as precision down to the exact number of bits. For floats we have similar control, being able to customize the size of the mantissa as well as the exponent (although in practice this is likely less relevant than being able to customize integer types). To learn more about this functionality for floats, we recommend to read the relevant section of the manual.
Strings
HDF5 itself provides access to both C-type strings and FORTRAN type strings. As R internally uses C-strings, only C-type strings are supported (i.e. strings that are NULL delimited). In terms of the size of the strings, there are fixed and variable length strings available.
str_fixed_len <- H5T_STRING$new(size = 20)
str_var_length <- H5T_STRING$new(size = Inf)These two types of strings have implications for efficiency and usability. For obvious reasons, variable length strings are more convenient as they are never too small hold a piece of information. However, internally in HDF5, these aren’t stored in the dataset itself - only a pointer to the HDF5-internal heap is stored. This has 2 implications:
- Retrieving the string is somewhat slower
- As the heap is not compressed, compression of datasets does not yield much space saving for variable length data
From this perspective, fixed length strings are considerably better as they are both faster (if not too long) and compressible. However, the user has to be careful that their strings aren’t getting too long, or they will be truncated.
Enum
The equivalent to factors in R are ENUM datatypes. These are stored internally as integers, but each integer has a string label attached to it. In contrast to R-factor variables, the integer values do not have to start at 1 and do not have to to consecutive either. In order to support this more flexible datatype also optimally on the R side, hdf5r comes with the factor_extended class. In the HDF5 API - each enum level is inserted one at a time. As this is rather inconvenient for a vector-oriented language like R, this functionality has not been exposed. We instead provide an R6-class constructor that lets us set all labels and values in one go.
For efficiency reasons, an integer datatype is automatically generated that provides exactly the needed precision in order to store the values of the enum. Given an enum, variable, we can also find out what labels and values it has
enum_example$get_labels()
enum_example$get_values()## [1] "Label 1" "Label 2" "Label 3"
## [1] -3 5 10In addition, we can also get the datatype back that the enum is based on
enum_example$get_super()## Class: H5T_INTEGER
## Datatype: undefined integerLogical values
A logical variable is a special case of an enum. It is internally based on a 1-byte unsigned integer that has a precision of 1-bit (so an n-bit filter will only store a single bit). Its internal values are 0 and 1 with labels FALSE and TRUE respectively. As a class, it is represented as an H5T_ENUM
logical_example <- H5T_LOGICAL$new(include_NA = TRUE)
## we could also use h5types$H5T_LOGICAL or h5types$H5T_LOGICAL_NA
logical_example$get_labels()
logical_example$get_values()## [1] "FALSE" "TRUE" "NA"
## [1] 0 1 2Note that doLogical has precedence over the labels parameter.
Compounds (Tables)
Tables are represented as COMPOUND HDF5 objects, which are the equivalent of C-struct. As R does not know this datatype natively, it has to be converted from structs to the list-based construct of R data-frames. Similar as with ENUMs, we don’t expose the underlying C-API that builds the compound on element at a time but instead provide constructors that create it in one go.
cpd_example <- H5T_COMPOUND$new(c("Double_col", "Int_col", "Logical_col"), dtypes = list(h5types$H5T_NATIVE_DOUBLE,
h5types$H5T_NATIVE_INT, logical_example))and similar to enums, we can also get back the column names, the classes of the datatypes as well as identifiers for the datatypes itself.
cpd_example$get_cpd_labels()## [1] "Double_col" "Int_col" "Logical_col"
cpd_example$get_cpd_classes()## [1] H5T_FLOAT H5T_INTEGER H5T_ENUM
## 13 Levels: H5T_NO_CLASS H5T_INTEGER H5T_FLOAT H5T_TIME ... H5T_NCLASSES
## 13 Values: -1 0 1 2 ... 11
cpd_example$get_cpd_types()## [[1]]
## Class: H5T_FLOAT
## Datatype: H5T_IEEE_F64LE
##
## [[2]]
## Class: H5T_INTEGER
## Datatype: H5T_STD_I32LE
##
## [[3]]
## Class: H5T_LOGICAL
## Datatype: H5T_ENUM {
## undefined integer;
## "FALSE" 0;
## "TRUE" 1;
## "NA" 2;
## }A textual description is also available
cat(cpd_example$to_text())## H5T_COMPOUND {
## H5T_IEEE_F64LE "Double_col" : 0;
## H5T_STD_I32LE "Int_col" : 8;
## H5T_ENUM {
## undefined integer;
## "FALSE" 0;
## "TRUE" 1;
## "NA" 2;
## } "Logical_col" : 12;
## }Complex values
We also have a way of representing complex variables, these are a compound object consisting of two double precision floating point columns. This also matches nicely the fact that internally in R, complex values are represented as a struct of doubles.
cplx_example <- H5T_COMPLEX$new()
cplx_example$get_cpd_labels()
cplx_example$get_cpd_classes()## [1] "Real" "Imaginary"
## [1] H5T_FLOAT H5T_FLOAT
## 13 Levels: H5T_NO_CLASS H5T_INTEGER H5T_FLOAT H5T_TIME ... H5T_NCLASSES
## 13 Values: -1 0 1 2 ... 11Arrays
A special datatype is the H5T_ARRAY. As datasets are itself arrays, they are not needed to represent arrays itself. Rather, the are useful in cases where one datatype is wrapped inside another, so mainly if a column of a compound object is supposed to be an array. So lets create an array and put it into a compound object together with some other columns
array_example <- H5T_ARRAY$new(dims = c(3, 4), dtype_base = h5types$H5T_NATIVE_INT)
cpd_several <- H5T_COMPOUND$new(c("STRING_fixed", "Double", "Complex", "Array"),
dtypes = list(str_fixed_len, h5types$H5T_NATIVE_DOUBLE, cplx_example, array_example))
cat(cpd_several$to_text())## H5T_COMPOUND {
## H5T_STRING {
## STRSIZE 20;
## STRPAD H5T_STR_NULLTERM;
## CSET H5T_CSET_ASCII;
## CTYPE H5T_C_S1;
## } "STRING_fixed" : 0;
## H5T_IEEE_F64LE "Double" : 20;
## H5T_COMPOUND {
## H5T_IEEE_F64LE "Real" : 0;
## H5T_IEEE_F64LE "Imaginary" : 8;
## } "Complex" : 28;
## H5T_ARRAY {
## [4][3] H5T_STD_I32LE
## } "Array" : 44;
## }And to see what this would look like as an R object
obj_empty <- create_empty(1, cpd_several)
obj_empty## Warning in format.data.frame(if (omit) x[seq_len(n0), , drop = FALSE] else x, :
## corrupt data frame: columns will be truncated or padded with NAs
obj_empty$Array## STRING_fixed Double Complex Array
## 1 0 0+0i 0
## [1] 0 0 0 0 0 0 0 0 0 0 0 0Variable length data types
And last, there are also variable length datatypes - corresponding to a list in R where each item of the list has the same datatype (general R list, where each item can have a different type cannot be represented in HDF5).
vlen_example <- H5T_VLEN$new(dtype_base = cpd_several)This would represent a list where each item is a table with an arbitrary number of rows.
Implementation details
In this section some of the details will be discussed that are likely only interesting for the technically inclined or someone who would want to extend the package itself.
Closing of unused ids and garbage collection
In this package, the C-API of HDF5 is being used. For the C-API, it is usually the programmer’s responsibility to close manually an HDF5-ID that is being used by calling the appropriate “close” function. If programs are not written very diligently, this can easily lead to memory-leaks.
As users of R are used to objects being automatically garbage-collected, such a behavior could pose a significant problem in R. In order to avoid any issues, the closing of HDF5-IDs is therefore done automatically using the R garbage collection mechanism.
For every id that is created in the C-code and passed back to R, an R6-class object is created that is non-cloneable. During creating, the finalizer (see reg.finalizer) is set so that during garbage collection of the R6-class object or when shutting down R, the corresponding HDF5 resources are being released.
In addition to this, all HDF5-IDs that are currently in use are being tracked as well (in the obj_tracker environment; not exported). The reason for this separate tracking is so that on demand, all objects that are currently still open in a file can be closed. The special challenge here is on the one-hand to track every R6 object that is in use in R, and at the same time not interfere with the normal operation of the R garbage collection mechanism. To this end, we cannot just save the environment itself in the obj_tracker (note that in R, an environment-object is always a pointer to the environment, not the whole environment itself). If we stored a pointer to the environment itself, the R garbage collector would never delete the environment as formally it would still be in use (in the obj_tracker). In order to prevent that, the following mechanism was implemented:
- Every HDF5-ID that is in use is wrapped inside an environment.
- A pointer to that environment is stored inside the R6-class as well as the obj_tracker
- This way, the R6-class is not referenced directly by the obj_tracker, however it is possible, by accessing the environment the ID is
- wrapped in through the object tracker to set the ID that is stored inside it to NA - thereby invalidating it.
- As the R6-class is only storing a pointer to the environment, for it the ID will now also appear as NA.
As mentioned, this was mainly implemented to allow for the closing of all IDs that are still open inside a file and to invalidate all existing R6-classes as well.
Opening and closing of files
In this context, let us quickly also discuss the special way HDF5 handles files. In HDF5, in principle a file can always only be opened once. This can lead to problems as users in R are used to being able to open files as often as they like. Furthermore, it is possible in HDF5 to close the ID of a file without closing all objects in the file. Then, however, the file actually stays open until the last ID pointing into the file is closed and it cannot be opened again without it.
Therefore, as already explained above (and as recommended by the HDF5 manual), do not discard or close files that still have open objects in them. It is preferable to keep the HDF5-file-id pointer around and close it when it is no longer needed (and all objects inside the file) using the close_all method.
Conversion of datatypes
A special feature of this package is the far-reaching and flexible implementation of data-conversion routines between R and HDF5. Routines have been implemented for all datatypes, string, data-frames, arrays and variable length (HDF5-VLEN) objects. Some are relatively straightforward, others are more complicated. Here, numeric datatypes can be tricky due to the limited ability of R to represent certain datatypes, specifically long doubles or 64bit-integers.
Numeric datatypes
For numeric datatypes, the situation is in certain circumstances a bit tricky. In general, R numerical objects are either represented as 64-bit floating point values (doubles) or 32-but integers. R switches relatively transparently between these types as needed (for computations, integers are converted to doubles and conversely, array positions can be addressed by doubles). The main issue when working with HDF5 occurs as R doesn’t have either a 64bit signed or unsigned integer datatype (and also not a long double). In order to work around this issue, the following conventions are being used
- The package uses the bit64 package to provide support for 64-bit integers. These are used extensively (e.g. for ids) and also for numeric integer data types.
- 32 bit and 64 bit floats from HDF5 are always returned as 64 bit floats in R. Writing 32 bit floats from R, may always incur loss of precision of the underlying 64 bit double that is used to represent it in R.
- For integer data types, any HDF5 integer type that can accurately be represented as a 32-bit signed integer will be returned to R as a regular integer (can be changed using flags). Any HDF5 64-bit integer can be returned as a signed 64-bit integer - with the option of returning it as a 32 bit integer or double if it can be done without loss of precision. For unsigned 64-bit integers, they will be returned as floats, incurring loss of precision but avoiding truncation.
An overview of how the data conversion is being done can be seen here:
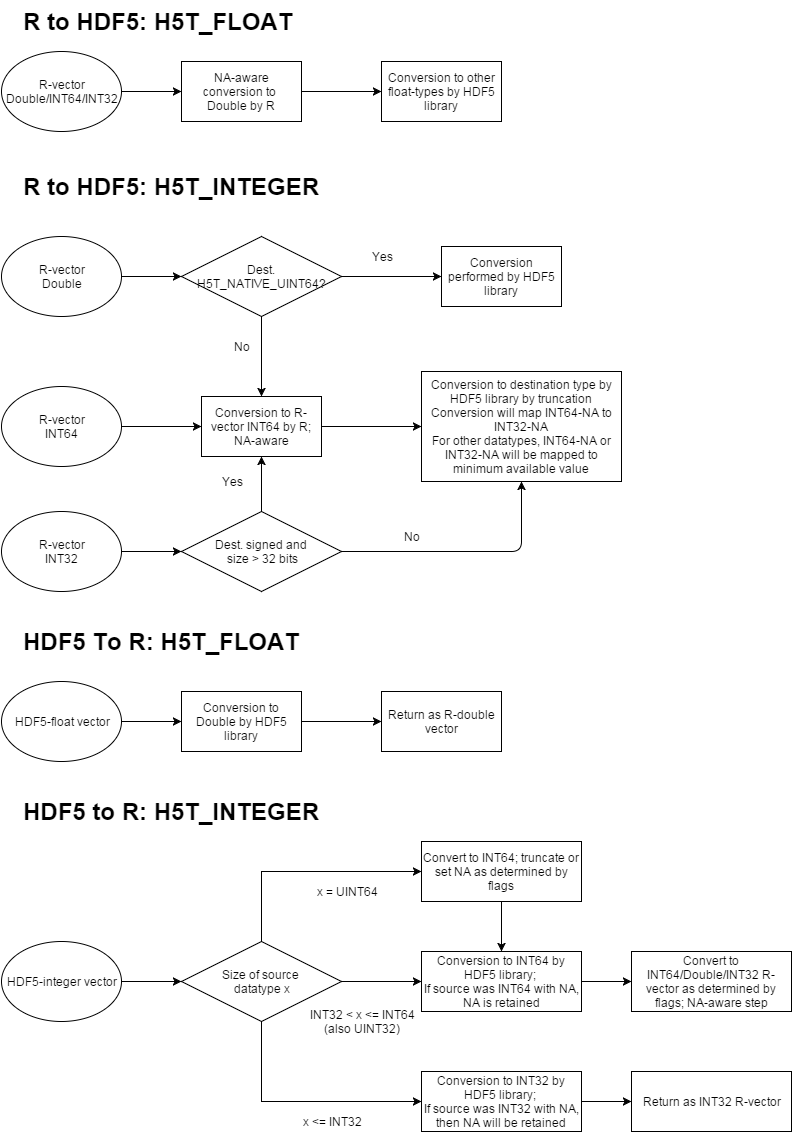
The underlying principle is that any internal conversion between R types is done by R (with the resulting handling of NA’s and overflows), whereas any conversion between R-types and Non-R-types is done by the HDF5 library (usually meaning that on overflow, truncation occurs).
Strings
In HDF5, strings can either be variable length or fixed length strings. In R, they are always variable length. Therefore, strings from R to HDF5 that are written into fixed-length fields will be truncated. Conversely, strings from HDF5 that are fixed length to R will only be returned up the the NULL character that ends strings in C.
Data-frames/Compounds
The situation is a bit more tricky for table-like objects. In R, these are data-frames, which internally are a list of vectors. In HDF5, a table is a Compound object, that is equivalent to C-struct - i.e. every row is represented together whereas in R every column is represented together. Each of these approaches has certain advantages, but the challenge here is to translate between them.
This is done in the straightforward manner. When converting from R to HDF5, the columns of the tables are copied into the struct whereas in the reverse direction, every struct is decomposed into the corresponding columns.
The Data-frame <-> Compound conversion is also extensively used for HDF5-API functions that return structs as result (and therefore return data-frames).
Arrays data-types
In HDF5, datasets itself can have arbitrary dimensions. In addition to that, there are also array-datatypes that allow for the inclusion for arrays e.g. inside a compound object. Translation to and from arrays is relatively straightforward and only involves setting the correct dim attribute in R.
In addition to that, however, there is small complication. In R, the first dimension is the fastest changing dimension. In HDF5 (same as in C), the last dimension is however the fastest changing one. For datasets, we work around this problem by always reversing the dimensions that are passed between R and HDF5 and therefore making the distinction transparent. For arrays, this is however a bit trickier. For example let us assume that we have a dataset that is a one-dimensional vector of length 10, each element of which is an array-datatype of length 4, resulting in a 10 x 4 dataset. However, it is now not quite clear how this should be represented in R. If we follow the notion, that the fastest changing dimension in R is the first one, the result would be a dataset with 4 rows and 10 columns, i.e. 10 x 4.
This does feel rather unintuitive, forcing a user to specify the second dimension to get all items of the array. Therefore, we have implemented it so that a 10 x 4 dataset is returned, with each row corresponding to the array-datatype. In order to achieve this we have to deviate from the ordering principle in HDF5. Where in HDF5, the elements of the first internal array are in position 1, 2, 3 and 4 (or 0 to 3 when you start counting at 0), in R they are now in position 1, 11, 21, and 31. In order to do this, we first internally read the HDF5 array into an R-array of shape 4 x 10 and then transpose the result.
Variable-length data types
In HDF5, there are also variable-length data types. Essentially, this corresponds to an R list-like object, with the additional restriction that every item of the list has to be of the same datatype. This is also how it is implemented. R list where all items are vectors (of arbitrary length) of the same type can be converted to HDF5-VLEN objects and vice versa.